| Vision Transformer的Pytorch代码实现和解读 | 您所在的位置:网站首页 › pytorch 官网 › Vision Transformer的Pytorch代码实现和解读 |
Vision Transformer的Pytorch代码实现和解读
|
Preface: 很久没用Transformer了,复习一下,主要讲解代码实现。 本实验在Google Colab下进行,有网络条件的可以直接进入:ViT in google colab (本来还想找个以前做的植苗分类(图像分类任务)做个resnet和ViT的性能对比,突然一阵胸闷,晚安了哈哈哈哈有缘再做) 关于本文,并不是完全按照ViT论文实现的Transformer结构,例如没有用到LaeyrNorm、没有用到位置编码,关于为什么没用,要如何用,放在文章最后一节扩展说明里。 正文:Transformer层的代码实现:import torch from torch import nn # 定义Transformer层模块 class TransformerLayer(nn.Module): # Transformer layer https://arxiv.org/abs/2010.11929 (LayerNorm layers removed for better performance) def __init__(self, c, num_heads): super().__init__() self.q = nn.Linear(c, c, bias=False) self.k = nn.Linear(c, c, bias=False) self.v = nn.Linear(c, c, bias=False) self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads) self.fc1 = nn.Linear(c, c, bias=False) self.fc2 = nn.Linear(c, c, bias=False) def forward(self, x): x = self.ma(self.q(x), self.k(x), self.v(x))[0] + x x = self.fc2(self.fc1(x)) + x return x由上面代码我们可以看出TransformerLayer的模块全是Linear层,意味着模型的输入,输出全是向量。这里提前透露一下,输入输出不仅都是向量,形状还相同,所以上面的TransformerLayer可以作为backbone中的一个Block。 下文中将把上面代码的self.q(x), self.k(x), self.v(x)记为Q、K、V,即Q=self.q(x), K=self.k(x), V=self.v(x) 注意力机制和多头注意力机制的公式和实现:上面的代码有基本pytorch基础的应该除了nn.MultiheadAttention都能看懂,那么这里简单讲解一下多头注意力机制: 在介绍多头注意力机制前,我们先介绍 注意力机制: Attention=softmax(\frac{QK^{T}}{\sqrt{d_k}})V ,这里的QKV三个向量分别是上面代码的self.q(x), self.k(x), self.v(x)三个线性层得到的三个向量, {d_k} 代表维度。通过上面公式我们可以得到 \frac{QK^{T}}{\sqrt{d_k}} 部分是一个数字,再softmax一下还是数字,不过变到[0,1]范围内了,接着0~1的一个常数乘V,这里V是向量,所以注意力机制的结果是向量,长度和V相同。即:注意力机制的输出形状和输入的Q、K、V形状都相同。 多头注意力机制:pytorch官网给的公式如下:  根据上面公式可以很容易看出,它其实就是将Q、K、V三个向量分别做三个不同的线性层,如 QW^Q 代表Q向量又经过了一个nn.Linear(input_dim,out_dim/num_heads),K和V同理。这样一个head实现的功能是先利用三个降维的线性层将QKV三个矩阵向量长度降低。例如输入x向量长度是128,即输入的形状为[1,128],假设设置head个数为4,那么每个head先把QKV三个向量分别降维到128/4=32,即Q、K、V的形状都由[1,128]变为[1,32],即对长度为32的QKV矩阵做上面注意力机制的公式,由注意力机制的公式可以知道这样一个Head的输出会是一个[1,32]形状的向量;同理我们设置的第二、三、四个Head也会生成[1,32]形状的向量,一共是4个[1,32]形状的向量。我们在dim=1的位置进行torch.concat,也就是将四个head的结果拼接,形状就变成[1,128],和我们假设的输入形状一致,实现多头注意力机制。 关于为什么要这样,QKV矩阵的含义是什么,本文不做讲解,本文主要讲解代码实现,想看原理可以参考我之前写的文章目录2.2.1下方的特别篇,QKV矩阵含义详解。 接下来我们进行验证输入输出形状是否一致,并测试不同Head数对模型推理速度的影响: 我们先对TransformerLayer模块进行测试: # 该测试代码主要验证 import time channel = 8192 for i in range(1,channel): # 注意:多头注意力机制的Head个数必须是能被输入向量长度整除的数 if not channel%i == 0: continue start = time.time() trans = TransformerLayer(c=channel,num_heads=i) x = torch.randn((1,channel)) # print("x.shape = ",x.shape) y = trans(x) # print("y.shape = ",y.shape) # 这里x和y的形状是一样的,即不改变形状 print("i={},times={}ms".format(i,round((time.time()-start)*1000,4)))结果为: i=1,times=5857.4948ms i=2,times=4933.2006ms i=4,times=5414.7344ms i=8,times=5487.505ms i=16,times=5039.0089ms i=32,times=6043.9403ms i=64,times=4991.6329ms i=128,times=5986.6595ms i=256,times=5032.8779ms i=512,times=5953.8522ms i=1024,times=4990.8755ms i=2048,times=5248.919ms i=4096,times=5520.247ms结论:TransformerLayer层并不会因为Head个数变多就计算量变大(因为多头拆分QKV以后每个向量变小了),但是具体会变快或者变慢是不一定的,总之Head个数对推理时间的影响不大。要注意这里Head个数必须是能被向量长度整除。 TransformerBlock:不熟悉ViT的看到上面估计都懵逼了,这不是做图像吗?怎么输入输出都是向量?其实是做了一个image2vector的操作,关于图to向量的操作也是有技巧的,关于原理参考我之前文章的第一部分: 这里直接上代码: class TransformerBlock(nn.Module): # Vision Transformer https://arxiv.org/abs/2010.11929 def __init__(self, c1, c2, num_heads, num_layers): super().__init__() self.conv = None if c1 != c2: # 如果TransformerBlock,即ViT模块输入和输出通道不同,提前通过一个卷积层让通道相同 self.conv = Conv(c1, c2) self.linear = nn.Linear(c2, c2) # learnable position embedding self.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers))) self.c2 = c2 def forward(self, x): if self.conv is not None: x = self.conv(x) b, _, w, h = x.shape p = x.flatten(2).permute(2, 0, 1) return self.tr(p + self.linear(p)).permute(1, 2, 0).reshape(b, self.c2, w, h)其实从代码来看很简单了: 我们把ViT看成一个模块,即TransformerBlock,这个模块可以改变特征图的通道个数,我们抽象地将TransformerBlock看成一个只能改变通道数的卷积神经网络,它对特征图的形状修改等价于nn.Conv2d(c1,c2),不过这里注意这里说的只是形状改变等价于只改变通道,并不能说它等价于2D卷积! 假设我们输入了一个特征图形状为[1,3,32,32], TransformerBlock只能改变通道数,假设我们期望改变通道数为64,即输出形状变成[1,64,32,32] # 这里并不是说TransformerBlock就绝对不能改变特征图的W和H,真想改的话改一下TransformerBlock内部的Conv模块就可以啦 **ViT模块总结**:第一步:通过Conv模块把输入特征图由[1,3,32,32]变成[1,64,32,32] 第二步:p =x.flatten(2).permute(2,0,1)。这一步作用就是上面的image2vector,这里p形状变成[1024, 1, 64],即image2vector将[Β, C, H, W]的特征图变成了[H*W, Β, C]的形状,但是要注意了!别直接用reshape,而是有具体细节的,也就是x.flatten(2).permute(2,0,1),原理参考我上面提到的知乎文章。 第三步:设置指定个数的TransformerLayer,功能就是不改变输入输出形状,只做注意力机制,此时的输出还是[H*W, Β, C]形状。 第四步:变回特征图。按步骤二的image2vector进行逆操作,变回特征图,形状为[Β, C, H, W]。 ViT模块推理测试:接下来我们做一个简单的测试: # Conv为卷积+BatchNorm2d+SiLU class Conv(nn.Module): # Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation) default_act = nn.SiLU() # default activation def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True): super().__init__() self.conv = nn.Conv2d(c1, c2, kernel_size=k, stride=s, padding=0, groups=g, dilation=d, bias=False) self.bn = nn.BatchNorm2d(c2) self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity() def forward(self, x): return self.act(self.bn(self.conv(x))) def forward_fuse(self, x): return self.act(self.conv(x)) # 这里就是上面提到的TransformerBlock,和上面代码一样的 class TransformerBlock(nn.Module): # Vision Transformer https://arxiv.org/abs/2010.11929 def __init__(self, c1, c2, num_heads, num_layers): super().__init__() self.conv = None if c1 != c2: self.conv = Conv(c1, c2) self.linear = nn.Linear(c2, c2) # learnable position embedding self.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers))) self.c2 = c2 def forward(self, x): if self.conv is not None: x = self.conv(x) b, _, w, h = x.shape p = x.flatten(2).permute(2, 0, 1) print("image2vector后向量的形状:",p.shape) return self.tr(p + self.linear(p)).permute(1, 2, 0).reshape(b, self.c2, w, h) transblock = TransformerBlock(c1=3,c2=64,num_heads=2,num_layers=4) x = torch.randn(2,3,32,32) y = transblock(x) print(y.shape)运行以后得到的结果是: image2vector后向量的形状: torch.Size([1024, 2, 64]) torch.Size([2, 64, 32, 32])另外给大家测试一下,如果特征图大点会怎样: transblock = TransformerBlock(c1=3,c2=64,num_heads=2,num_layers=4) x = torch.randn(2,3,128,128) y = transblock(x) print(y.shape)运行结果为:   我是在google colab平台上测试的,也就是说12G的内存,相当于3080Ti显卡,特征图大小仅为[1,3,128,128]跑个Transformer直接就崩溃了。这里崩溃原因主要在于我设置C2(也就是C_out)=64,其实相当于先把特征图变成[1,64,128,128],还是有一点点一点点大的(真的大吗哈哈哈哈),反正!总而言之就是ViT超级吃内存!没几张卡慎重玩! ViT推理性能:可以看到CPU环境的话一层TransformerLayer就得费时好久,多几层可就太久了~而且费时主要在注意力机制这块  至于为什么注意力机制慢?直接看个图吧:多头注意力机制里的if else可真多  关于ViT的优化还是挺多,下次再写 扩展说明:1、位置信息编码关于ViT,其实还有位置编码、Norm层没在本文代码中体现: 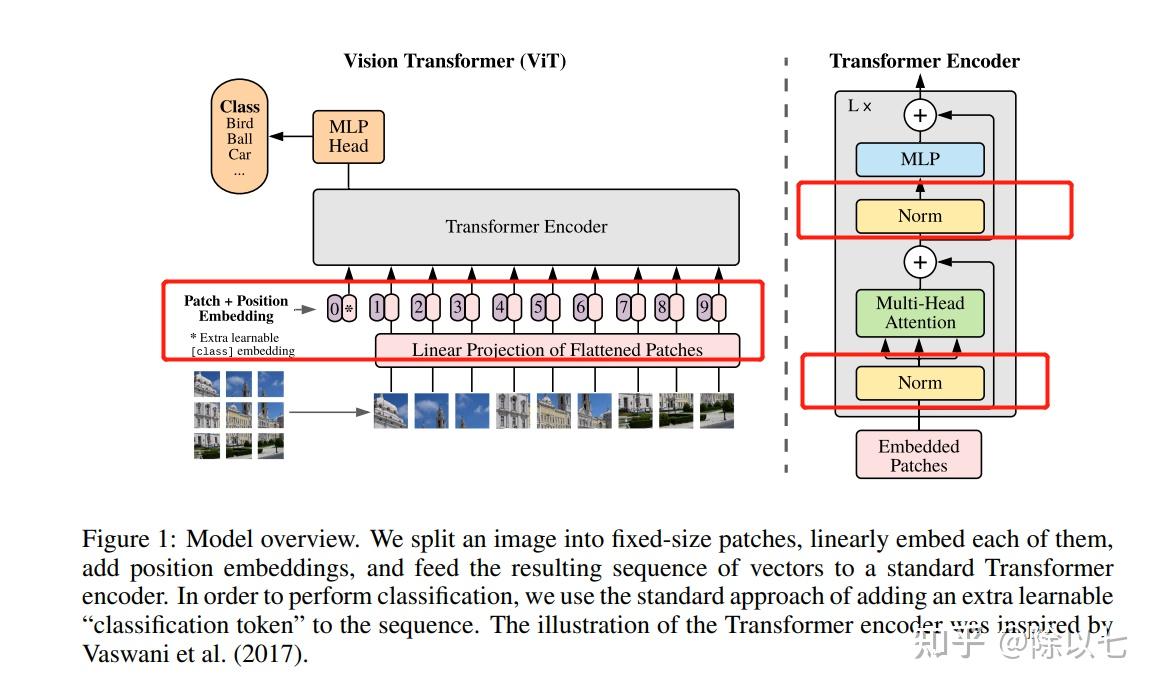 首先先说为什么没写:本文用的ViT选自yolov5中的模块,经过实验不加LayerNorm效果会更好;关于位置信息编码:  总之,实验证明了不加也可以。那我非要加呢? 首先位置编码: class PositionalEncoding(nn.Module): def __init__(self, d_model, dropout=0.1, max_len=5000): super(PositionalEncoding, self).__init__() self.dropout = nn.Dropout(p=dropout) # Compute the positional encodings once in log space. pe = torch.zeros(max_len, d_model) # shape = [5000,hidden_dim=256] print("positional_encodings.shape = ",pe.shape) position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # position是一个5000行1列的Tensor,为0到4999 div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # 这里div_term是exp([0, 2, 4, ... , 256] * C), C = (-math.log(10000.0) / d_model),是一个负数 # 公式拆一下,设A=[0, 2, 4, ... , 256],C = -math.log(10000.0) / d_model, # div_term = exp(A*C) = e^(A*C) = (e^C)^A = [e^ln(10000)]^(A/d_model) = 10000^(-A/d_model)= 1/10000^(A/d_model),即上图中的PE pe[:, 0::2] = torch.sin(position * div_term) # 神奇原作者,写的真复杂 这里用除法不行吗?非得上面exp里加负号 pe[:, 1::2] = torch.cos(position * div_term) # pe.shape = [5000,256] print(pe.shape) print(pe[0,:20]) print(pe[2,:20]) pe = pe.unsqueeze(0).transpose(0, 1) print("pe_to_vec",pe.shape) # shape = ([5000, 1, 256]) self.register_buffer('pe', pe) def forward(self, x): # 此处x.shape=[5000,1,256],但是我们的图向量长度只有14*14=196,所以只从5000份里取前196份Embedding print("self.pe[:x.size(0), :].shape:",self.pe[:x.size(0), :].shape) # shape=[5,1,256],即PE是一个固定好的编码向量,我们有几张图就抽几个PE出来 x = x + self.pe[:x.size(0), :] print("位置编码输出x.shape",x.shape) # x.shape = [5, 196, 256] return self.dropout(x)核心的位置编码其实就是 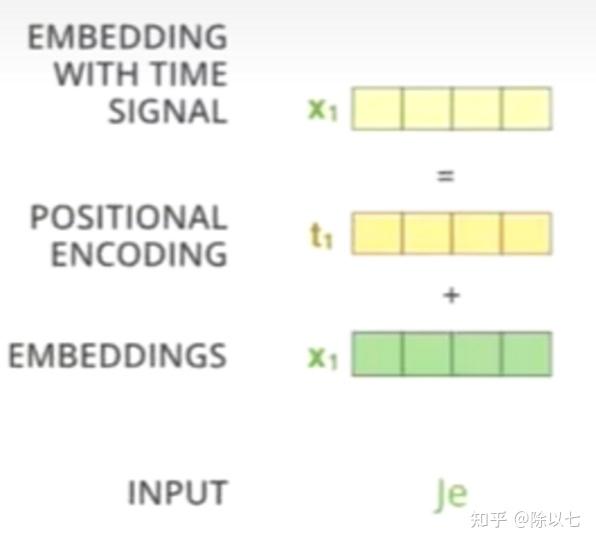 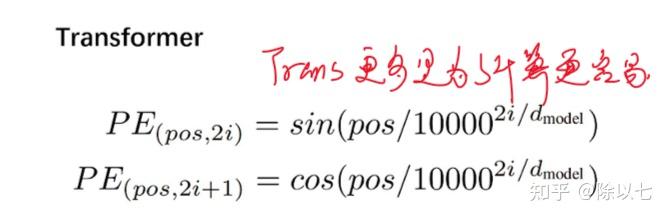 2、关于Encoder和Decoder 2、关于Encoder和Decoder这里ViT作为backbone、或者作为图像分类的分类器,是不需要用到Transformer的Decoder结构的,只有用于目标检测等领域时才利用Decoder作为Head |
【本文地址】